Abstract
The compiler design is a well researched area of computer science. Typically, compiler designers use a parser generator framework like YACC or PCCTS to construct lexer, scanner, parser, and abstract syntax tree. With the arrival of expression templates and template meta-programming, it is possible to construct a parser by simply using the template meta-programming technique. The Spirit library is object-oriented recursive-decent parser implemented in C++ using expression templates and meta-programming. In Spirit the parser is constructed during the compile time using a combination of primitive parsers and fusing them through template meta-programming. TinyPascal is a practical application of Spirit framework.
Introduction
TinyPascal is a subset of standard Pascal language. Its original grammar is inspired by the grammar found on the website referenced under [9]. In addition to the referenced grammar, TinyPascal defines loops and floating point data type. The compiler consists of the parser, abstract syntax tree generator, symbol table generator, semantic checker, and code generators. The Parser is implemented using the Spirit parser framework. Code generators are MIPS assembler emitter and Sun Microsystems JavaTM bytecode emitter.
It is important to note that TinyPascal is not designed to be used as programming tool. The sole purpose of the project is to demonstrate compiler design using Spirit parser framework.
Following is the document outline with brief description of each section:
TinyPascal: Describes TinyPascal language; presents language definition in Extended Backus-Normal Form (EBNF).
Parsing: Introduces Spirit parser framework and discusses expression templates as utilized in Spirit. Spirit implementation of TinyPascal grammar is included and it is accompanied by extensive discussion on template meta-programming.
Abstract Syntax Tree: Introduces Spirit AST factory and how it is utilized for Abstract Syntax Tree generation. Discusses design decisions of TinyPascal abstract syntax tree generation.
Symbol Table: Explains symbol table construction and abstract syntax tree traversal.
Semantics: Discusses implementation details of semantic checker. Discussion on type derivation, type checking, and type conversion is included.
Code Generation: Explains MIPS assembler code generation and Sun Microsystems JavaTM bytecode generation.
Error Reporting: Introduces the issue of error checking and recovery.
Compiler Class Diagram: Documentation on compiler implementation.
TinyPascal Editor: Introduces TinyPascal source code editor.
References: Lists references used for the project implementation.
TinyPascal
TinyPascal is a simple language based on Pascal programming language. The language consists of only 11 keywords and supports basic arithmetic operations. Despite simplicity, the implementation addresses series of language design issues and demonstrates solution all those issues. Simplicity is one of the key features of TinyPascal project. Each stage of the language design is presented in its simplest form addressing fundamental design issues at that stage.
TinyPascal consists of 11 keywords and they are following:
KEYWORD: program
DESCRIPTION: Marks the beginning of every program and provides the name of the program. The keyword PROGRAM must be followed by an identifier, which is the name of the program. Following example marks the beginning of the program with the name “test”.
EXAMPLE:
program(test); …
KEYWORD: begin
DESCRIPTION: Marks the beginning of a block. There can be zero to many blocks within a program. The example below demonstrates an empty block. Blocks may be nested.
EXAMPLE:
PROGRAM(TEST);
BEGIN
END.
KEYWORD: end
DESCRIPTION: Marks the end of a block.
EXAMPLE: See keyword begin.
KEYWORD: var
DESCRIPTION: Marks the beginning of the global variable declaration section. There can be at most one variable declaration section. All global variables must be declared within this section. In the example below, variable X is declared to be an integer.
EXAMPLE:
program(TEST);
VAR
X:INTEGER;
BEGIN
END.
KEYWORD: for
DESCRIPTION: Marks the beginning of the for-loop. The example below loops through the block 5 times, and increments the loop variable at the end of each iteration. At first, the variable “i” has the value of 1, then 2, 3, 4, and finally the value of 5.
EXAMPLE:
for i:=1 to 5 do
begin
end
KEYWORD: to
DESCRIPTION: Used only within the for-loop (see above) construct. The keyword “TO” denotes that loop variable will be incremented.
EXAMPLE: See keyword for.
KEYWORD: downto
DESCRIPTION: Used only within the for-loop (see above) construct. The keyword “DOWNTO” denotes that the loop variable will be decremented. The example below loops through the loop block 5 times, and decrements the loop variable at the end of each iteration. At first the variable “i” has the value of 5, then 4, 3, 2, and finally the value of 1.
EXAMPLE:
for i:=5 downto 1 do
begin
end
KEYWORD: do
DESCRIPTION: Used only within the for-loop construct. The keyword “DO” marks the beginning of the loop block.
EXAMPLE: See keywords for and downto.
KEYWORD: writeln
DESCRIPTION: Used for writing to the standard output. The Keyword “WRITELN” can have 0, 1, or many comma separated arguments. If there is at least one argument, it must be surrounded by parentheses. If there are no arguments, “WRITELN” simply outputs a newline character; otherwise each argument is delimited by a newline character. Arguments can be constant values, variables, or any expression. Following example demonstrates three most common cases where “WRITELN” is used.
EXAMPLE:
Case 1:
…
writeln;
…
Output:
>
>
Case 2:
…
writeln(5);
…
Output:
>5
>
Case 3:
…
writeln(5,6,7);
…
Output:
>5
>6
>7
>
KEYWORD: integer
DESCRIPTION: Declares the type of a variable to be an integer. The example below declares single variable of type integer.
EXAMPLE:
program(x);
var x:integer;
begin
end.
KEYWORD: real
DESCRIPTION: Declares the type of a variable to be a floating point value. The example below declares single variable of type real.
EXAMPLE:
program(x);
var
x:real;
begin
end.
TinyPascal is case insensitive. Each program must be terminated by a dot character marking the end of a program. After the dot character, there must be no statements. Comments are denoted with “{}” character pair. For example:
{ This is a program }
program(test);
var
K,Z,D : INTEGER;
begin
{
This is a multiline comment within a block.
Note case insensitive variable usage!
}
k:=1; z:=3; d:=5;
end.
Data Types
TinyPascal supports two fundamental data types: INTEGER and REAL. Both data types are signed and their widths depend upon the code generator. At this point the code generators have identical translations for both data types. Because TinyPascal compiles to MIPS assembler and JavaTM bytecode, data types are translated directly to appropriate types supported by the corresponding system. In MIPS, an INTEGER translates to a word, which is a 32 bit signed integer stored in two’s complement format. The REAL is translated to a float, which is a 32 bit IEEE 754 floating-point number. In Java, an INTEGER translates to an int, which is a 32 bit signed integer stored in two’s complement format, while a REAL is translated to a float, which is a 32 bit IEEE 754 floating-point number.
Identifiers
Identifiers are considered to be all strings that are not keywords. In addition, identifier must start with alphabetical character followed by any alphanumeric character. Alphabetical characters are considered to be the set of all letters from English alphabet [a-zA-Z]. Alphanumeric characters are the set of all alphabetical characters combined with the set of digits [0-9].
Operators
TinyPascal supports addition, subtraction, division, and multiplication of INTEGERS and REALS. The operator precedence confirms to the standard operator precedence. TinyPascal supports grouping operators (parentheses), which modify the operator precedence in usual manner. Operators can be of mixed type. During assignment, automatic type conversion is performed. The type conversion is discussed in “Semantics” section.
Loops
TinyPascal provides a looping mechanism in form of for-loops. For-loops are defined to be the following (EBNF):
ForStatement
= FOR OpAssign (TO | DOWNTO) Expression DO
Statement
Here, FOR, TO, DOWNTO, and DO are keywords. For the definition of non-terminals like OpAssign, Expression, and Statement, please refer to TinyPascal grammar section.
It is important to stress the fundamental difference between TinyPascal and standard Pascal regarding the loop definition. In standard Pascal, the loop variable cannot be modified within the loop statement. TinyPascal does not set such limitation i.e. the loop variable can be modified anywhere in the program including the loop block.
TinyPascal Grammar
The following is TinyPascal grammar in Extended Backus-Normal Form:
Program
= ProgramHeading
GlobalDeclarationPart+
MainStatementPart
DOT
ProgramHeading
= PROGRAM Identifier SEMI
GlobalDeclarationPart
= VarDeclaration
VarDeclaration
= VAR
VarDecl+
VarDecl
= Identifier (COMMA Identifier)* COLON Type SEMI
Type
= INTEGER | REAL
MainStatementPart
= BEGIN
Statement (SEMI Statement)*
END
OpAssign
= Identifier ASSIGN Expression
Statement
= MainStatementPart |
OpAssign |
WritelnStatement |
ForStatement |
Epsilon
ForStatement
= FOR OpAssign (TO | DOWNTO) Expression DO
Statement
WritelnStatement
= WRITELN (LPAREN Expression (COMMA Expression)* RPAREN) |
Epsilon
Expression
= Term ((PLUS Term) | (MINUS Term))*
Term
= Factor ((MULT Factor) | (DIV Factor))*
Factor
= Identifier |
RealFactor |
IntegerFactor |
LPAREN Expression RPAREN
Here, PROGRAM, BEGIN, END, FOR, DO, TO, DOWNTO, WRITELN, VAR, INTEGER, and REAL stand for corresponding keywords. PLUS, MINUS, MULT, and DIV represent arithmetic operators. LPAREN and RPAREN stand for left and right parenthesis. COMMA, COLON, and SEMI represent characters comma, colon, and semicolon, and finally ASSIGN represents combination of two characters “:=”, which is standard Pascal assignment operator.
Parsing
Generally, the parser is generated using popular parser generators like YACC and PCCTS. In such cases, parser generator framework reads a configuration file that contains the grammar, and generates the code that parses the language defined by the same grammar. Once the code for the parser is generated, it is included as a part of the compiler project.
TinyPascal follows similar approach. There is a grammar specified in EBNF and a parser framework generates the code to parse the same grammar. However, there is one fundamental difference: TinyPascal relies on C++ compiler and template meta-programming to generate the parser code. More specifically, TinyPascal utilizes parser generator framework [3] to implement a parser that generates abstract syntax tree during the parsing step. Following link introduces Spirit parser framework, how it works, as well as different intricacies associated with Spirit programming. The user is encouraged to read following article:
Expression templates and meta-programming in boost::Spirit
TinyPascal Parser
The TinyPascal parser is entirely implemented using the Spirit parser framework. As mentioned earlier, Spirit is the object oriented recursive-decent parser framework. Original EBNF language definition of TinyPascal contained left-recursion. In order to define the language using Spirit, left recursion had to be eliminated. The following left recursion elimination technique was adopted from Spirit [3] documentation:
Let’s consider following TinyPascal grammar definition part:
Term
= Factor |
Term MULT Factor |
Term DIV Factor
It is evident that such definition contains left recursion in the form A = B | (A C B), where A, B, C, and D are terminals and non-terminals defined within the grammar. Using simple redefinition of non-terminal A, we can define A using right recursion:
A = B H
H = (C B H) | epsilon (epsilon = match on no input)
Since X = Y | epsilon is equivalent to X = Y? (Y? matches Y zero or one time), we can rewrite right recursion to the following:
H = (C B H)?
Since X = (Y X)? is equivalent X = Y* (Y* matches Y zero or many times), we can rewrite our equation once again to be:
H = (C B)*
Finally, H can be embedded into original equation like:
A = B H = B (C B)*
Applying above derived transformation to TinyPascal grammar, we get the following:
Term
= Factor ((MULT Factor) | (DIV Factor))*
Relevant Class: TinyPascal::Parser::CAG_TinyPascalGrammar
Abstract Syntax Tree
Parse trees are in-memory representation of the program. Similarly, abstract syntax trees are in memory representation of the program, focusing on the program function rather than on the syntax. TinyPascal utilizes trees as an intermediate step between parsing and code generation. In this way, the parsing step is separated from the code generation step, which allows an easy modification of the one or the other. It is simple to add another code generation module independent of other parsing modules.
As a consequence of using the Spirit parser framework, the abstract syntax tree is generated during the parsing step. The Spirit provides a function that takes the grammar, checks the syntax and generates the abstract syntax tree. Upon successful parsing, abstract syntax tree is generated as an array of arrays, utilizing STL’s (Standard Template Library) vector data structure. However, the Spirit differentiates the parse tree and the abstract syntax tree generation. The Spirit documentation states that the underlying logic behind the parse tree and abstract syntax tree generation is similar. In addition, Spirit allows parts of the tree to be generated using the parse tree policy, while other parts can be generated using the abstract syntax tree policy. Such mix-and-match functionality of the Spirit framework allows the user to tailor the abstract syntax tree generation according to their needs.
It is important to stress the difference between the AST (abstract syntax tree) and the PT (parse tree) generation. According to the Spirit documentation, parse tree generation simply creates a node for each rule that is parsed. For each sub-rule, the parse tree algorithm simply creates a sub-node. The AST generation is somewhat different. If a node that is generated contains only a single sub-node, no new level is created. The rule to create the node is simply “overlooked” and the sub-node is generated to be the new node. In this way, if we have any number of rules that contains only a single sub-node, only two nodes are generated: the first and the last. However, such feature is not enough for AST generation. Following paragraph explains additional features necessary for successful AST generation.
Spirit AST Generation
The Spirit allows abstract syntax tree generation to be influenced by utilizing directives. Directives are functors that manipulate tree nodes after the tree is generated. (Functors in C++ are simply structures that overload “()” operator. In this way, the structure can be utilized as a function, with all of the characteristics of an object. Functors are also called function objects.) For instance, TinyPascal utilizes directives to eliminate node generation for dot character that denotes the end of program. In addition, no nodes are generated for semicolon because of its pure syntactical function.
One of the most important directives in Spirit is the root_node_d directive. Root_node_d directive simply states that the rule should be marked as the root node. All other sibling rules should be its children. In this way it is possible to generate the proper AST for arithmetic operations. For instance, when parsing A=B+C, B+C would be considered as siblings. Marking the rule that parses character + to be root node, the tree is transformed so that the “+” is the parent and A and B are its children. Such features are desired for the code generation during the tree traversal.
Similarly to the root_node_d directive, the Spirit provides a directive to ignore specific rules during the AST generation. The directive is called no_node_d. As mentioned earlier, characters as dot, semicolon, parenthesis, or certain keywords do not have any syntactical meaning to the program and its nodes should not be present within the AST. TinyPascal does not ignore all keywords during the AST generation. Such feature is utilized for clarity of AST graphical representation.
Just as certain nodes can be forced to be the root node, there are nodes that should be forced to be a leaf node. The Spirit provides a directive called token_node_d to perform this function. The Token_node_d directive is utilized for parsing identifiers.
In addition to the tree manipulation directives, the Spirit provides a way to tag each rule with a 32 bit integer for identification purposes. In this way, when a rule is recognized and its node is generated, the node is tagged with a predefined integer. Such feature allows simpler rule recognition during the AST traversal.
The following is TinyPascal grammar’s implementation in Spirit. Note the use of directives and identifiers for AST generation:
//! Grmmar used for parsing language
class CAG_TinyPascalGrammar : public grammar<CAG_TinyPascalGrammar>
{
public:
//! Define constants for each node
static const int ProgramID = 1;
static const int ProgramHeadingID = 2;
static const int GlobalDeclarationPartID = 3;
static const int MainStatementPartID = 4;
static const int IdentifierID = 5;
static const int VarDeclarationID = 6;
static const int VarDeclID = 7;
static const int RealFactorID = 8;
static const int TypeID = 9;
static const int ForStatementID = 10;
static const int StatementID = 11;
static const int ExpressionID = 12;
static const int WritelnStmtID = 13;
static const int OpAssignID = 14;
static const int TermID = 15;
static const int FactorID = 16;
static const int IntegerFactorID = 17;
//! Default constructor
CAG_TinyPascalGrammar() {}
//! Define nested class as required by Spirit framework
template <typename ScannerT> class definition
{
public:
//! Parameterized constructor defines grammar
definition(CAG_TinyPascalGrammar const& /*self*/)
{
#ifdef BOOST_SPIRIT_DEBUG
BOOST_SPIRIT_DEBUG_RULE(program);
BOOST_SPIRIT_DEBUG_RULE(program_heading);
BOOST_SPIRIT_DEBUG_RULE(global_declaration_part);
BOOST_SPIRIT_DEBUG_RULE(main_statement_part);
BOOST_SPIRIT_DEBUG_RULE(identifier);
BOOST_SPIRIT_DEBUG_RULE(var_declaration);
BOOST_SPIRIT_DEBUG_RULE(var_decl);
BOOST_SPIRIT_DEBUG_RULE(type);
BOOST_SPIRIT_DEBUG_RULE(statement);
BOOST_SPIRIT_DEBUG_RULE(expression);
BOOST_SPIRIT_DEBUG_RULE(writeln_stmt);
BOOST_SPIRIT_DEBUG_RULE(term);
BOOST_SPIRIT_DEBUG_RULE(factor);
BOOST_SPIRIT_DEBUG_RULE(op_assign);
BOOST_SPIRIT_DEBUG_RULE(for_statement);
#endif
/**************************************************************
* Keyword Helpers (This is used to avoid confusion between
* a identifier and a keyword.)
***************************************************************/
keywords
= _T("program"), _T("begin"), _T("end"), _T("var"),
_T("integer"), _T("real"), _T("writeln"), _T("for"),
_T("to"), _T("downto"), _T("do");
/**************************************************************
* Token Helpers (Single Characters)
***************************************************************/
chlit<TCHAR> DOT('.');
chlit<TCHAR> SEMI(';');
chlit<TCHAR> COLON(':');
chlit<TCHAR> PLUS('+');
chlit<TCHAR> MINUS('-');
chlit<TCHAR> MULT('*');
chlit<TCHAR> DIV('/');
chlit<TCHAR> EQUALS('=');
chlit<TCHAR> LPAREN('(');
chlit<TCHAR> RPAREN(')');
chlit<TCHAR> COMMA(',');
/**************************************************************
* Token Helpers (Multiple Characters)
***************************************************************/
inhibit_case<strlit<> > ASSIGN = as_lower_d[":="];
inhibit_case<strlit<> > PROGRAM = as_lower_d["program"];
inhibit_case<strlit<> > BEGIN = as_lower_d["begin"];
inhibit_case<strlit<> > END = as_lower_d["end"];
inhibit_case<strlit<> > VAR = as_lower_d["var"];
inhibit_case<strlit<> > INTEGER = as_lower_d["integer"];
inhibit_case<strlit<> > REAL = as_lower_d["real"];
inhibit_case<strlit<> > WRITELN = as_lower_d["writeln"];
inhibit_case<strlit<> > FOR = as_lower_d["for"];
inhibit_case<strlit<> > TO = as_lower_d["to"];
inhibit_case<strlit<> > DOWNTO = as_lower_d["downto"];
inhibit_case<strlit<> > DO = as_lower_d["do"];
/**************************************************************
* Productions
***************************************************************/
program
= program_heading >>
!global_declaration_part >>
main_statement_part >>
no_node_d[DOT];
program_heading
= no_node_d[keyword_d[PROGRAM]] >> identifier >> no_node_d[SEMI];
global_declaration_part
= var_declaration;
var_declaration
= keyword_d[VAR] >> +var_decl;
var_decl
= identifier >>
*(no_node_d[COMMA] >> identifier) >>
no_node_d[COLON] >>
root_node_d[type] >>
no_node_d[SEMI];
type
= INTEGER | REAL;
main_statement_part
= keyword_d[BEGIN] >>
statement >> *(no_node_d[SEMI] >> statement) >>
keyword_d[END];
op_assign
= identifier >> root_node_d[ASSIGN] >> expression;
statement
= main_statement_part |
op_assign |
writeln_stmt |
for_statement |
no_node_d[epsilon_p];
for_statement
= keyword_d[FOR] >> op_assign >> (keyword_d[TO] | keyword_d[DOWNTO])
>> expression >> keyword_d[DO] >> statement;
writeln_stmt
= root_node_d[WRITELN] >>
((no_node_d[LPAREN] >>
expression >> *(no_node_d[COMMA] >> expression) >>
no_node_d[RPAREN]) |
no_node_d[epsilon_p]);
expression
= term >>
*((root_node_d[PLUS] >> term) |
(root_node_d[MINUS] >> term));
term
= factor >>
*((root_node_d[MULT] >> factor) |
(root_node_d[DIV] >> factor));
real_factor
= number_d[strict_real_p];
integer_factor
= number_d[int_p];
factor
= identifier |
real_factor |
integer_factor |
inner_node_d[LPAREN >> expression >> RPAREN];
identifier
= token_node_d[
lexeme_d[
(alpha_p >> *(alnum_p)) - (keywords >> anychar_p - alnum_p)
]];
}
//! Keyword helper
symbols<int, TCHAR> keywords;
//! Productions
rule<ScannerT, parser_context<>, parser_tag<ProgramID> > program;
rule<ScannerT, parser_context<>, parser_tag<ProgramHeadingID> > program_heading;
rule<ScannerT, parser_context<>, parser_tag<GlobalDeclarationPartID> >
global_declaration_part;
rule<ScannerT, parser_context<>, parser_tag<MainStatementPartID> > main_statement_part;
rule<ScannerT, parser_context<>, parser_tag<IdentifierID> > identifier;
rule<ScannerT, parser_context<>, parser_tag<VarDeclarationID> > var_declaration;
rule<ScannerT, parser_context<>, parser_tag<VarDeclID> > var_decl;
rule<ScannerT, parser_context<>, parser_tag<TypeID> > type;
rule<ScannerT, parser_context<>, parser_tag<StatementID> > statement;
rule<ScannerT, parser_context<>, parser_tag<ExpressionID> > expression;
rule<ScannerT, parser_context<>, parser_tag<WritelnStmtID> > writeln_stmt;
rule<ScannerT, parser_context<>, parser_tag<TermID> > term;
rule<ScannerT, parser_context<>, parser_tag<FactorID> > factor;
rule<ScannerT, parser_context<>, parser_tag<OpAssignID> > op_assign;
rule<ScannerT, parser_context<>, parser_tag<ForStatementID> > for_statement;
rule<ScannerT, parser_context<>, parser_tag<RealFactorID> > real_factor;
rule<ScannerT, parser_context<>, parser_tag<IntegerFactorID> > integer_factor;
//! Override start function to return starting production
rule<ScannerT, parser_context<>, parser_tag<ProgramID> > const& start() const
{ return program; }
};
}
For more information on additional directives and AST generation, please refer to Spirit documentation [3].
Following are some examples of AST as generated by TinyPascal:
{ Simplest program }
program test1;
begin
end.
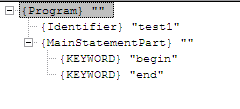
{ Variable declaration list }
program test3;
var
x,y:integer;
begin
end.

program loop2;
var
i:integer;
x:integer;
begin
x:=17;
for i:=1 to (x*2)+6 do
writeln(x+i);
end.

{********************************
* Author: Amer Gerzic
* Description: Compute factorial
********************************}
program factorial;
var
factorial, i, value : integer;
begin
{
Set factorial to the desired
value
}
factorial := 6;
value := 1;
writeln(factorial);
for i:=1 to factorial do
value := value * i;
writeln(value);
end.

Additional AST examples can be produced by TinyPascal GUI software.
Abstract Syntax Tree Traversal
Once the abstract syntax tree is created, TinyPascal utilizes it for semantic checking and code generation. During both steps, the compiler traverses the tree in the post-order fashion. As mentioned earlier, the Spirit generates the AST as a vector of vectors, so that each parent node contains its children in a vector of nodes. Following is the structure of an AST as created by the Spirit. Screenshots are taken from Visual Studio 2005 debugger. The screen shot below presents the program test3 (from previous section) as shown in Visual Studio 2005 debugger.
As presented in the previous screen shot, the m_AST structure is a vector of nodes. In this case only single node is present at position 0. When the node 0 is expanded it is evident that its members are a value and its children. The member children is a vector of children nodes. Traversing children nodes we can find same pattern.
TinyPascal traverses such structure by simply using recursion. Following is the pseudo code:
void visit(vector<…> &SubTree)
{
// visit all children
for(int i=0; i<SubTree.size(); ++i)
{
// visit all children of the children
visit(SubTree[i].children);
}
}
The initial parameter for visit function is the m_AST object because m_AST is already of type vector<…>. More accurate tree traversal examples can be found in the TinyPascal source code. Especially interesting are the code generation classes.
Symbol Table
TinyPascal utilizes the symbol table to enforce semantic rules. Semantic rules are defined to be necessity for each symbol to be defined before its use. In TinyPascal the symbol table is implemented using hash map data structure. After the parsing step, AST is created. AST is traversed and each node is visited. During the traversal, TinyPascal visits nodes that are responsible for variable definition. At that time the compiler is capable of detecting the name and the type of all declared variables. The Name/type pair is stored into a hash map. As the symbol table is built, the compiler detects if a symbol is defined multiple times. If such situation is detected, the symbol table object reports a compile error and the compilation is aborted.
Once the symbol table is built, the symbol table is passed to the semantic checker to check if all symbols are properly defined. Semantic checking is explained in the following section.
Relevant Class: TinyPascal::Semantics::CAG_TPSymbolTable
Semantics
In order to demonstrate type conversion and type checking process, TinyPascal provides two fundamental data types, real and integer. During the parsing process, TinyPascal checks the syntax and determines if a string belongs to the language that is defined by the grammar. After successful parsing, the Spirit framework creates an abstract syntax tree. However, the parsing process does not enforce semantic rules defined by the language. In addition, the parsing process does not enforce any type compatibility checks.
In order to enforce type compatibility, TinyPascal performs type derivation during the compile time (static). Once the abstract syntax tree is generated, the same tree is passed to a Symbol Table object for symbol table construction. Once the symbol table is constructed, to each of defined symbols is assigned a type. Using the information provided by the symbol table, the compiler is capable of deriving the type of each expression. Type derivation is performed by traversing the tree in post-order. During the tree evaluation (for type), the following rules are enforced:
- Adding/Subtracting/Dividing/Multiplying two integer yields an integer.
- Adding/Subtracting/Dividing/Multiplying two reals yields a real.
- Adding/Subtracting/Dividing/Multiplying integer and real yields a real.
Using the rules above, each expression is evaluated and resulting type is determined. The type of each expression is embedded into the abstract syntax tree. At this point, the AST contains all necessary ingredients for type checking. Type checking is performed by abstract syntax tree traversal. However, during the type checking, only the nodes for the assignment and the loop are considered. The assignment is evaluated by checking the type of both children. The loop is evaluated by checking the type of the loop variable and the loop expression. During teh type checking, only the following rules are enforced:
- Assigning an integer to an integer is permitted (obviously).
- Assigning a real to a real is permitted (obviously).
- Assigning an integer to a real is permitted.
- Assigning a real to an integer produces a warning, because there is possible information loss.
- Loop variable must be of the type integer.
- Loop expression, must evaluate to an integer.
Relevant Class: TinyPascal::Semantics::CAG_TPTypeChecker
Code Generation
TinyPascal generates MIPS assembler code, which can be executed using the MIPS assembler simulator (SPIM) that is referenced under [12]. In addition, TinyPascal generates Sun Microsystems JavaTM class file as specified by the Java Virtual Machine specifications [10]. Java class file that is generated by the TinyPascal can be executed using Sun’s Java Virtual Machine.
MIPS Assembler Code Generator
As already mentioned, TinyPascal has two code generators. One of them is the MIPS assembler code generator. At this point, the reader is encouraged to reference the book that explains MIPS assembly language [11]. Following paragraphs will heavily rely on familiarity of MIPS assembly language.
TinyPascal generates MIPS assembly code from the abstract syntax tree, which is generated during the parsing phase. MIPS assembly listing is created by traversing the AST in post-order fashion. It is important to note that the TinyPascal does not utilize any register selection algorithm to optimally allocate registers and hence does not perform the code optimization utilizing register allocation. Actually, TinyPascal does not perform any optimization at the code generation level. Code generation of the MIPS assembler is performed utilizing the stack feature of the MIPS machine. For this reason, MIPS code generator never uses more than two registers at any time. In addition, the MIPS generator emits comments within the MIPS assembly listing. In this way, the user can determine which part of the AST was traversed when the specific code section was generated. Such feature could be utilized for educational purposes.
In its simplest form, every MIPS program has the following structure:
# Here we have variable declaration part
.text
.globl mainmain:
# Here goes the program
li $v0, 10 syscall
As the comment already denotes, there are two sections where the MIPS assembler generator emits the code. Variable declaration part is simply populated by traversing the symbol table. Each entry in the symbol table is an identifier followed by the type. During the MIPS code generation phase, each identifier must be defined within the assembly listing. Main program section is generated by traversing the MainStatementPart node of the abstract syntax tree. Other nodes do not contain any relevant information for main program section.
As already pointed out, the variable declaration is performed by traversing the symbol table and emitting the assembly listing. Each integer is translated into MIPS word data type, while each real is translated into a float. Following example is the direct result of the MIPS code generation. Let’s consider the following TinyPascal program:
program test10;
var
x : integer;
y : real;
begin
end.
The program test10 contains one variable of the type integer and one of the type real. The program declares variables without performing any other useful function. Compiling the program test10, the following MIPS assembler code is generated:
# _test10
# ----- BEGIN: Emit Symbol Table
.data_x:
.word 0_y:
.float 0.0
writeln:
.asciiz "\n"
# ----- END : Emit Symbol Table
.text
.globl mainmain:
# ----- BEGIN: Emit Main Statement Part
# ----- END : Emit Main Statement Part
li $v0,10
# syscall to exit the program
syscall
As expected, the code generator traversed the symbol table and emitted all the entries found in the symbol table. In addition, the assembly code contains comments, which are automatically generated for clarity. It is important to note that all identifiers emitted by the MIPS generator are preceded with an underscore character. This is to avoid the name collision of identifiers and MIPS keywords. For instance, if identifiers were emitted without any modification, the identifier “add” would be a legal identifier in TinyPascal, but an illegal identifier in the MIPS assembly language, because “add” is a MIPS assembler keyword.
Another important observation is that the variable declaration (in MIPS) requires the value assignment. Hence, the TinyPascal sets all defined variables to initial value of 0.
Once the all variables are defined, the code generator traverses the MainStatementPart of the abstract syntax tree. Traversal is performed in post-order, which means that root is emitted only after all its children are emitted. Because TinyPascal supports only four arithmetic operations, the code of those is trivial. All binary operations are emitted by pushing of both operands onto the stack, popping them from the stack, evaluating the binary operation, and finally, pushing the result onto the stack. The following section presents the pseudo code that is utilized for pushing and popping variables/values onto the stack.
Pushing a value/variable onto the stack:
- Load variable/value into a register
- Decrease stack pointer by 4 – this is because in MIPS the integers and floats are 4 bytes wide. Also stack “grows” from higher addresses to lower
- Store the register at the address pointed by the stack pointer
Popping value/variable from the stack:
- Load the value at the current stack pointer address
- Increase stack pointer by 4 – same as push, but reverse!
- Move the register value into the variable – if a constant then simply use the register.
It is important to note that pushing and popping of integers is different than pushing and popping of reals. For reals, MIPS utilizes the floating point registers, while for integers, general 32 bit registers are utilized. Reader is encouraged to reference the following member functions of CAG_SPIMCodeGenerator class:
- PushIdentifier – pushes a variable onto the stack, while differentiating between integer and real.
- PushIntegerFactor – pushes integer value onto the stack.
- PushRealFactor – pushes real value onto the stack.
Type Issue
As already mentioned, binary operations are generated by popping two operands from the stack, performing the operation, and pushing the result onto the stack. Such translation is trivial when both operands are of the same type. However, the issue arises when operand types are different. The issue becomes apparent because the MIPS assembler provides two different instruction sets for the operations performed on floats and integers. In other words, the addition can only add either two integers or two floats. Also, the addition of floats has different mnemonic than the addition of integers. Finally, the addition of floats performs addition on 32 bit floating point registers, while addition of integers performs the operation on 32 bit integer registers. This is not only the case for addition, but also for any other operation (loading, storing, moving, arithmetic operations etc.).
TinyPascal provides the automatic type conversion, which is implemented implemented at MIPS code generation level. In order to accomplish the type conversion, code generator must detect if an arithmetic operation or the assignment is performed on mixed types. Such detection is trivial, because the AST contains the type information of each node. If such case is encountered, the code generator converts types utilizing MIPS instructions that are specifically designed for type conversion. Furthermore, it is important to stress, that the only conversion performed is conversion from integer to float. Float is converted to an integer only if a float is assigned to an integer. In following example both of mentioned cases are presented:
TinyPascal source:
program test10;
var
x : integer;
y : real;
begin
y:=1+2.0;
x:=y;
end.
In program above, the line 6 contains the addition of an integer and a float. Line 7 performs the assignment of a float to an integer. Both operations force the compiler to perform the type conversion. Following is the assembly listing generated by MIPS code generator:
# _test10
# ----- BEGIN: Emit Symbol Table
.data_x:
.word 0_y:
.float 0.0
writeln:
.asciiz "\n"
# ----- END : Emit Symbol Table
.text
.globl mainmain:
# ----- BEGIN: Emit Main Statement Part
# ----- BEGIN: Emit Assignment
# ----- BEGIN: Emit Expression
# ----- BEGIN: Push Integer Factor
li $t0,1
add $sp, $sp, -4
sw $t0,($sp)
# ----- END : Push Integer Factor
# ----- BEGIN: Push Real Factor
li.s $f0,2.0
add $sp, $sp, -4
s.s $f0,($sp)
# ----- END : Push Real Factor
# ----- BEGIN: Emit Addition
l.s $f0,($sp)
add $sp, $sp, 4
l.s $f1, ($sp)
add $sp, $sp, 4
cvt.s.w $f1, $f1
add.s $f0, $f1, $f0
s.s $f0, ($sp)
# ----- END : Emit Addition
# ----- END : Emit Expression
l.s $f0,($sp)
add $sp, $sp, 4
s.s $f0,_y
# ----- END : Emit Assignment
# ----- BEGIN: Emit Assignment
# ----- BEGIN: Push Identifier
l.s $f0,_y
add $sp, $sp, -4
s.s $f0,($sp)
# ----- END : Push Identifier
l.s $f0,($sp)
add $sp, $sp, 4
cvt.w.s $f0, $f0
mfc1 $t0, $f0
sw $t0,_x
# ----- END : Emit Assignment
# ----- END : Emit Main Statement Part
li $v0,10
# syscall to exit the program
syscall
Looking at the code, we can locate the section where the two values are added. For clarity, the section is highlighted in red color. Analyzing the code reveals that both values are popped form the stack into corresponding floating point registers. However, one of these values is an integer, which is stored in the memory using the two’s complement format. This is incompatible with the floating point notation specified by the MIPS specifications (IEEE 754 single precision). In other words, when an integer is moved into a floating point register, it is moved bit by bit. Memory representation of an integer is completely different than the memory representation of a float (even though they have the same value). Hence a conversion must be performed. MIPS assembler provides a mechanism for such conversion. Using cvt.s.w instruction the content of a register is converted from an integer to the float, preserving the arithmetic value of the register. Upon successful conversion, the arithmetic operation can be performed by adding the two floating values.
The second case presents the assignment of a floating point value to an integer. TinyPascal generates a warning every time such conversion is performed due to the possibility of information loss. MIPS assembler code that is highlighted in blue presents such conversion. At first, a value is popped from the stack into a floating point register (because we are popping floating point value). Utilizing the conversion instruction set (cvt.w.s), the same value is converted to a word (equivalent to an integer). However, the value is still in a floating point register, which is not accessible by the integer instruction set. Hence the value must be moved into an integer register, so that the assignment can be performed. MIPS assembler provides an instruction called “mfc1”, which essentially moves a value from a floating point coprocessor into an integer register.
Reader is encouraged to analyze following member functions of the CAG_SPIMCodeGenerator:
- EmitAssignment – emits assignment node
- EmitDivision – emits division node
- EmitAddition – emits addition node
- EmitMultiplication – emits multiplication node
- EmitSubtraction – emits subtraction node
Writeln
In MIPS, emitting the “Writeln” statement is trivial. MIPS assembly language provides built-in system I/O services for writing to the standard output. “Writeln” statement is emitted by popping a value from the stack, storing it into the appropriate register, and calling the appropriate system service. The reference to all MIPS system I/O services can be found on page 112 of the book referenced under [11]. The following are system I/O services utilized by the TinyPascal:
- To print an integer: $v0 = 1 and $a0 = value to be printed
- To print a float: $v0 = 2 and $f12 = value to be printed
- To print a string: $v0 = 4 and $a0 = address of string in memory
Here, $v0, $f12, and $a0 are registers.
It is important to note that every value is printed on a separate line. To achieve such effect, the code generator emits a newline character after every system call. The system call 4 is responsible for printing newline character to the output. The following example prints a float and an integer:
TinyPascal code:
program test10;
var
x : integer;
y : real;
begin
writeln(x);
writeln(y);
end.
MIPS Assembler code:
# _test10
# ----- BEGIN: Emit Symbol Table
.data_x: .word
0_y: .float 0.0
writeln: .asciiz "\n"
# ----- END : Emit Symbol Table
.text
.globl mainmain:
# ----- BEGIN: Emit Main Statement Part
# ----- BEGIN: Emit Writeln Statement
# ----- BEGIN: Push Identifier
lw $t0,_x
add $sp, $sp, -4
sw $t0,($sp)
# ----- END : Push Identifier
lw $a0,($sp)
add $sp, $sp, 4
li $v0, 1
syscall
la $a0, writeln
li $v0, 4
syscall
# ----- END : Emit Writeln Statement
# ----- BEGIN: Emit Writeln Statement
# ----- BEGIN: Push Identifier
l.s $f0,_y
add $sp, $sp, -4
s.s $f0,($sp)
# ----- END : Push Identifier
l.s $f12,($sp)
add $sp, $sp, 4
li $v0, 2
syscall
la $a0, writeln
li $v0, 4
syscall
# ----- END : Emit Writeln Statement
# ----- END : Emit Main Statement Part
li $v0,10
# syscall to exit the program
syscall
Please note the definition of the “writeln” variable within the data segment of the assembler listing. “Writeln” variable is simply defined to be a newline character that is printed after every “writeln” statement. The reader is encouraged to examine the EmitWritlnStatement member function of the CAG_SPIMCodeGenerator class.
Loops
TinyPascal supports for-loops. Translation of loops into MIPS assembly language is performed by the evaluation of the AST loop node. Emitting a loop in MIPS assembly language is performed by utilizing jump family of instructions, in combination with labels. Following is the pseudo code of the loop statement as emitted by the assembler generator:
1.Evaluate(OpAssign) - LoopVariable contains initial value
LOOP:
2.Evaluate(Expression) - result will be pushed on stack
3.Compare(Expression, LoopVariable) - if true then jump to DONE
- If keyword "downto" is used then comparison should be LoopVariable >= Expression
- If keyword "to" is used then comparison should be LoopVariable <= Expression.
4.Evaluate(Statement)
5.Modify LoopVariable
- If keyword "downto" is used then Decrease(LoopVariable)
- If keyword "to" is used then Increase(LoopVariable)
6.Jump LOOP
DONE:
Looking at the pseudo code of the loop translation algorithm, it is obvious that LOOP and DONE are MIPS assembler labels. At first, a value is assigned to the loop variable. Assigning the value to the loop variable is performed only once. The section between the LOOP and DONE is called loop-body. Within the loop-body, the first step is to evaluate the expression that the loop variable compares to. Once the expression is evaluated, the result is compared with the value of the loop variable. If the termination requirement is not met, loop-statement is evaluated. At the end of the loop-body, loop-variable is increased/decreased and the loop-body is evaluated from beginning.
The following is an example of the algorithm presented above:
program test10;
var
x : integer;
begin
for x:=0 to 10 do
begin
end
end.
Following assembly code is generated:
# _test10
# ----- BEGIN: Emit Symbol Table
.data_x: .word 0
writeln: .asciiz "\n"
# ----- END : Emit Symbol Table
.text
.globl mainmain:
# ----- BEGIN: Emit Main Statement Part
# ----- BEGIN: Emit For Loop
# ----- BEGIN: Emit Assignment
# ----- BEGIN: Push Integer Factor
li $t0,0
add $sp, $sp, -4
sw $t0,($sp)
# ----- END : Push Integer Factor
lw $t0,($sp)
add $sp, $sp, 4
sw $t0,_x
# ----- END : Emit Assignmentlabel_0:
# ----- BEGIN: Push Integer Factor
li $t0,10
add $sp, $sp, -4
sw $t0,($sp)
# ----- END : Push Integer Factor
lw $t1,($sp)
add $sp, $sp, 4
lw $t0,_x
bgt $t0, $t1,label_1
# ----- BEGIN: Emit Main Statement Part
# ----- END : Emit Main Statement Part
lw $t0,_x
addi $t0, $t0, 1
sw $t0,_x
b label_0label_1:
# ----- END : Emit For Loop
# ----- END : Emit Main Statement Part
li $v0,10
# syscall to exit the program
syscall
The reader is encouraged to analyze following member functions of ACG_SPIMCodeGenerator class:
- EmitForLoop – emits loop
- GetLabel – generates unique label at runtime.
File Naming Convention
Once the compilation is successful, TinyPascal compiler generates an assembler file with *.s extension. The file name is derived from the program name, specified within the TinyPascal source. For example, if the program name is test10 (from examples above), the assembler file name will be _test10.s.
Relevant Class: TinyPascal::Emitter::CAG_SPIMCodeGenerator
Java Bytecode Generator
As already pointed out, TinyPascal is capable of generating Sun Microsystems JavaTM class file. It is important to mention that the Java bytecode generator (included in TinyPascal package) is not capable of generating all of the features supported by the Java Virtual Machine. Java bytecode generator implements features necessary for TinyPascal language translation.
Similar to MIPS code generator, Java bytecode generator creates a class file by traversing the AST in post-order. Following sections will heavily rely on reader’s familiarity with the Java Virtual Machine and the reader is encouraged to reference JVM specification as referenced under [10].
As specified by the JVM Specifications [10], Java Virtual Machine is stack-based virtual machine. In other words, every instruction is expecting parameters to be on the stack. Being stack-based virtual machine, JVM does not contain registers, so that the register selection algorithm is not needed. Hence the Java Bytecode emitter is implemented similarly to MIPS assembler code generator
Looking at the JVM Specifications and the class file definition, we can see that the class file is nothing else but a data structure stored onto the disk. JVM loads the class file and stores each section into appropriate data structure for parsing and execution. For a complete class file definition, please refer to JVM Specifications [10].
During the Java code generation, TinyPascal generates single class file per program. In its simplest form, a class file contains nothing else but class name and default constructor, which is of the form ().Following is the functions that adds the default constructor to the class file:
void CAG_JavaBytecodeGenerator::AddDefaultConstructor()
{
// Add Method
method_info* pMethodInfo = new method_info();
pMethodInfo->access_flags = 0x0001;
pMethodInfo->name_index = AddUtf8Info("<init>");
pMethodInfo->descriptor_index = AddUtf8Info("()V");
// Add Code Attributed for Method
Code_attribute* pCodeAttribute = new Code_attribute();
pCodeAttribute->attribute_name_index = AddUtf8Info("Code");
pCodeAttribute->max_stack = 1;
pCodeAttribute->max_locals = 1;
pCodeAttribute->code.push_back(aload_0);
pCodeAttribute->code.push_back(invokespecial);
// Construct invokespecial parameter - Methodref Info structure
u2 index = AddMethodrefInfo("java/lang/Object", "<init>", "()V");
Emit(index, pCodeAttribute->code);
pCodeAttribute->code.push_back(_return);
pMethodInfo->attributes.push_back(pCodeAttribute);
methods.push_back(pMethodInfo);
}
As expected, the function simply adds appropriate structures to create a default constructor method. At first, the function adds method info structure to be stored into methods array. Method info structure serves as the reference to the method definition. The second structure is the code attribute structure, which defines default constructor’s behavior. In our case, default constructor simply calls the default constructor of the base class, which is the Object class. The call to the default constructor of the Object class is performed using invokespecial instruction, which pops index of the method reference from the stack and calls the appropriate method.
Due to the nature of the TinyPascal code translation, each class file contains additional methods that are added automatically to the class. First, TinyPascal adds the main method and references to prinln methods with three different signatures. Main method serves as the application entry point. References to println methods serve for translation of writeln statements, which will be explained later. Following is the function, which adds the main method code:
void CAG_JavaBytecodeGenerator::AddMainMethod()
{
// Add main method of the class -> here is where everything happens
method_info* pMethodInfo = new method_info();
pMethodInfo->access_flags = 0x0001 | 0x0008;
pMethodInfo->name_index = AddUtf8Info("main");
pMethodInfo->descriptor_index = AddUtf8Info("([Ljava/lang/String;)V");
m_pMainMethodCode = new Code_attribute();
m_pMainMethodCode->attribute_name_index = AddUtf8Info("Code");
pMethodInfo->attributes.push_back(m_pMainMethodCode);
methods.push_back(pMethodInfo);
}
Similar to default constructor code, the main method is nothing else but reference to the method structure stored in methods array. It is important to note that the main method code structure is stored as a global variable for later use. This is due to the fact that the above code creates skeleton of the main method. Main method functionality is implemented later as the AST is traversed.
Following are instructions with opcodes that are utilized for bytecode generation:
_return = 0xb1,
getstatic = 0xb2,
putstatic = 0xb3,
invokevirtual = 0xb6,
invokespecial = 0xb7,
aload_0 = 0x2a,
ldc_w = 0x13,
f2i = 0x8b,
i2f = 0x86,
fmul = 0x6a,
fdiv = 0x6e,
fadd = 0x62,
fsub = 0x66,
imul = 0x68,
idiv = 0x6c,
iadd = 0x60,
isub = 0x64,
if_icmplt = 0xa1,
if_icmpgt = 0xa3,
iconst_m1 = 0x02,
iconst_0 = 0x03,
iconst_1 = 0x04,
iconst_2 = 0x05,
_goto = 0xa7
For detailed explanation of each instruction, please refer to JVM specifications [10].
Similar to MIPS assembly code generation, Java bytecode generator emits variable declaration by traversing the symbol table. Following is variable declaration emitter function:
bool CAG_JavaBytecodeGenerator::EmitVarDecl(
CAG_TPSymbolTable::SymbolTableType& SymbolTable)
{
/*
Emitting varible declaration is nothing else but doing following:
1. Create field of the corresponding type
2. Create reference to that field for later use
*/
CAG_TPSymbolTable::SymbolTableType::const_iterator iter = SymbolTable.begin();
for(iter; iter != SymbolTable.end(); ++iter)
{
string strType;
if(iter->second == CAG_TPSymbolTable::real)
strType = "F";
else if(iter->second == CAG_TPSymbolTable::integer)
strType = "I";
AddField("_" + iter->first, strType);
AddFieldrefInfo(m_strClassName, "_" + iter->first, strType);
}
return true;
}
As we can see, adding a variable to a class file means adding a field definition to the same class file. Adding a field means that the name and the type descriptors must be added. As in MIPS, each name is preceded with an underscore characters to avoid name collision with keywords and other predefined words. As defined by the JVM specifications, each field must have a type. TinyPascal has two data types the real, and the integer, which are translated as Java’s floats and integers. Corresponding type strings are “F” and “I”. After adding the field, java bytecode generator must add a field reference to the same field, so that the newly added field can be referenced within the class. The field reference is used for pushing the field onto the stack.
To demonstrate, let us consider the same program as presented as MIPS example:
program test10;
var
x : integer;
y : real;
begin
end.
Using java disassembler, we can look at the generated class file:
public class _test10 extends java.lang.Object
minor version: 0
major version: 49
Constant pool:
const #1 = Asciz _test10;
const #2 = class #1; // _test10
const #3 = Asciz java/lang/Object;
const #4 = class #3; // java/lang/Object
const #5 = Asciz java/io/PrintStream;
const #6 = class #5; // java/io/PrintStream
const #7 = Asciz println;
const #8 = Asciz ()V;
const #9 = NameAndType #7:#8;// println:()V
const #10 = Method #6.#9; // java/io/PrintStream.println:()V
const #11 = Asciz (I)V;
const #12 = NameAndType #7:#11;// println:(I)V
const #13 = Method #6.#12; // java/io/PrintStream.println:(I)V
const #14 = Asciz (F)V;
const #15 = NameAndType #7:#14;// println:(F)V
const #16 = Method #6.#15; // java/io/PrintStream.println:(F)V
const #17 = Asciz java/lang/System;
const #18 = class #17; // java/lang/System
const #19 = Asciz out;
const #20 = Asciz Ljava/io/PrintStream;;
const #21 = NameAndType #19:#20;// out:Ljava/io/PrintStream;
const #22 = Field #18.#21; // java/lang/System.out:Ljava/io/PrintStream;
const #23 = Asciz ;
const #24 = Asciz Code;
const #25 = NameAndType #23:#8;// "":()V
const #26 = Method #4.#25; // java/lang/Object."":()V
const #27 = Asciz main;
const #28 = Asciz ([Ljava/lang/String;)V;
const #29 = Asciz _x;
const #30 = Asciz I;
const #31 = NameAndType #29:#30;// _x:I
const #32 = Field #2.#31; // _test10._x:I
const #33 = Asciz _y;
const #34 = Asciz F;
const #35 = NameAndType #33:#34;// _y:F
const #36 = Field #2.#35; // _test10._y:F
{
public static int _x;
Signature: I
public static float _y;
Signature: F
public _test10();
Signature: ()V
Code:
Stack=1, Locals=1, Args_size=1
0: aload_0
1: invokespecial #26; //Method java/lang/Object."":()V
4: return
public static void main(java.lang.String[]);
Signature: ([Ljava/lang/String;)V
Code:
Stack=0, Locals=1, Args_size=1
0: return
}
As expected, there are two variables _x and _y, which correspond to x and y variables from the test10 program. Their entries can be found in the constant pool table (first part of the disassembled program). Their types are “I” and “F”, which symbolizes an integer and a float (real in TinyPascal). In addition, generated class file contains the default constructor and the main method, which at this point performs no significant function. It is important to note that the variable declaration results in generation of static variables within the Java class file. This is due to the fact that all variables defined within the TinyPascal are global, which is similar to static fields in Java language. TinyPascal is not an object oriented language as opposed to the Java language and hence the translation is appropriately adapted. Similar to the Java language, TinyPascal specification requires each variable to be initialized to 0, which does not have to be explicitly performed in java class file, because JVM performs it automatically.
After variable declaration, Java bytecode generator proceeds with MainStatementPart traversal for the code generation. At this point, all code generation is performed within the code section of the main statement part. Traversal is performed in post-order, which means that root is emitted only after all its children have been emitted.
As earlier mentioned TinyPascal supports 4 arithmetic operations, which are addition, subtraction, division, and multiplication. Due to the fact that JVM is a stack based virtual machine, all the operations are performed in similar fashion to the MIPS assembler code generation. First, both operands are pushed onto the stack and popped when the operation is performed. The result of each operation is immediately pushed onto the stack. Unlike MIPS assembler code, where all operations had to be implemented manually, JVM provides instructions for pushing and popping variables/constants onto the stack (ldc_w (constant numbers), getstatic (variables)). Pushing onto the stack in JVM is performed by pushing a 16 bit index of the appropriate entry onto the stack. In other words, pushing and popping of different structures is performed by pushing and popping their indices that are defined within the constant pool array. It is important to note that all constants must be translated to appropriate data structure and stored inside the constant pool. This is fundamentally different from the MIPS assembler, because all numbers must be declared and translated beforehand (similar to variable declaration), while in MIPS, the numbers can simply be inserted into assembler listing.
Type Issue
Java bytecode emitter faces similar type issues presented during the MIPS assembly code generation. Each operation pops operands from the stack and performs the operation. Similar to MIPS language, JVM contains two different instruction sets for integers and floats. Unlike MIPS, the register issue is not present, because JVM is a stack based virtual machine. Considering the fact that type issue was resolved during the MIPS code generation, similar approach is taken. Using AST and type derivation, code generator is capable to “look forward” and detect a type issue, which would cause type conversion.
However, the type conversion in JVM must be approached differently. This is due to the fact that popping of operands is not performed manually. In MIPS, popping of operands was performed manually and the type conversion was performed after the element was popped from the stack. In JVM popping of elements is performed automatically by the instruction. In this case, the instruction expects correct data types on the stack. Hence the approach to solve the type issue used in MIPS could not be applied to Java code generation. The last chance to take control over the type conversion was rather at the point where the operand was pushed onto the stack. Let’s consider following example (from MIPS section):
program test10;
var
x : integer;
y : real;
begin
y:=1+2.0;
x:=y;
end.
Test10 program contains two type conversion cases which are translated into following class file:
public class _test10 extends java.lang.Object
minor version: 0
major version: 49
Constant pool:
const #1 = Asciz _test10;
const #2 = class #1; // _test10
const #3 = Asciz java/lang/Object;
const #4 = class #3; // java/lang/Object
const #5 = Asciz java/io/PrintStream;
const #6 = class #5; // java/io/PrintStream
const #7 = Asciz println;
const #8 = Asciz ()V;
const #9 = NameAndType #7:#8;// println:()V
const #10 = Method #6.#9; // java/io/PrintStream.println:()V
const #11 = Asciz (I)V;
const #12 = NameAndType #7:#11;// println:(I)V
const #13 = Method #6.#12; // java/io/PrintStream.println:(I)V
const #14 = Asciz (F)V;
const #15 = NameAndType #7:#14;// println:(F)V
const #16 = Method #6.#15; // java/io/PrintStream.println:(F)V
const #17 = Asciz java/lang/System;
const #18 = class #17; // java/lang/System
const #19 = Asciz out;
const #20 = Asciz Ljava/io/PrintStream;;
const #21 = NameAndType #19:#20;// out:Ljava/io/PrintStream;
const #22 = Field #18.#21; // java/lang/System.out:Ljava/io/PrintStream;
const #23 = Asciz ;const #24 = Asciz Code;
const #25 = NameAndType #23:#8;// "":()V
const #26 = Method #4.#25; // java/lang/Object."":()V
const #27 = Asciz main;
const #28 = Asciz ([Ljava/lang/String;)V;
const #29 = Asciz _x;
const #30 = Asciz I;
const #31 = NameAndType #29:#30;// _x:I
const #32 = Field #2.#31; // _test10._x:I
const #33 = Asciz _y;
const #34 = Asciz F;
const #35 = NameAndType #33:#34;// _y:F
const #36 = Field #2.#35; // _test10._y:F
const #37 = int 1;
const #38 = float 2.0f;
{
public static int _x;
Signature:
Ipublic static float _y;
Signature:
Fpublic _test10();
Signature:
()V Code:
Stack=1, Locals=1, Args_size=1
0: aload_0
1: invokespecial #26; //Method java/lang/Object."":()V
4: return
public static void main(java.lang.String[]);
Signature: ([Ljava/lang/String;)V
Code:
Stack=2, Locals=1, Args_size=1
0: ldc_w #37; //int 1
3: i2f
4: ldc_w #38; //float 2.0f
7: fadd
8: putstatic #36; //Field _y:F
11: getstatic #36; //Field _y:F
14: f2i
15: putstatic #32; //Field _x:I
18: return
}
Looking at the disassembled code, we can see that the complete code translation was performed within the main method code section. For clarity, relevant code is marked in red. At the code offset of 0, we can find instruction to push an integer onto the stack. The instruction at the code offset of 3 is the instruction “i2f”. The instruction “i2f” pops an integer from the stack, converts it to a floating point value, and pushes the same integer back onto the stack. This is fundamentally different from MIPS code generator because the type conversion is performed immediately after the operand is pushed onto the stack. Similarly, at the code offset 4 the value 2.0 is pushed onto the stack. In this case no type conversion is necessary and the operation can be performed (in this case the floating point addition). Using putstatic instruction, the resulting value is stored into variable y.
Next interesting issue is addressed at the code offset 11, where the value of the variable y is pushed onto the stack. Once again, TinyPascal code generation detects that two types are incompatible and immediately performs the type conversion (in this case back to an integer). Finally, the value is popped and stored into x.
Besides the type conversion issue, there is an additional issue specific to the Java bytecode emitter. Java virtual machine’s memory organization is defined to be in big-endian format. Also, the floating point values are stored in IEEE 754 binary format. Unlike MIPS assembly code where each constant can simply be embedded into the assembly listing, such conversion must be performed manually during the Java bytecode conversion. Current Java bytecode generator does not perform automatic floating point conversion, but rather relies that the host machine stores all numbers in IEEE 754 floating point format. However, Java bytecode generator performs an automatic endianess detection and appropriate conversion.
Writeln
Writeln statement is emitted by simply using the built-in Java library println method. Java provides println with multiple signatures: 1. Without parameters, 2. With an integer parameter, and 3. With a floating point parameter. As already mentioned, the method references for all three methods are automatically included during the class file initialization. Following example demonstrates the usage of the println methods.
program test10;
var
x : integer;
y : real;
begin
writeln(x);
writeln(y);
end.
Here, we are printing an integer and a float. The code is translated into the following JVM class file:
public class _test10 extends java.lang.Object
minor version: 0
major version: 49
Constant pool:
const #1 = Asciz _test10;
const #2 = class #1; // _test10
const #3 = Asciz java/lang/Object;
const #4 = class #3; // java/lang/Object
const #5 = Asciz java/io/PrintStream;
const #6 = class #5; // java/io/PrintStream
const #7 = Asciz println;
const #8 = Asciz ()V;
const #9 = NameAndType #7:#8;// println:()V
const #10 = Method #6.#9; // java/io/PrintStream.println:()V
const #11 = Asciz (I)V;
const #12 = NameAndType #7:#11;// println:(I)V
const #13 = Method #6.#12; // java/io/PrintStream.println:(I)V
const #14 = Asciz (F)V;
const #15 = NameAndType #7:#14;// println:(F)V
const #16 = Method #6.#15; // java/io/PrintStream.println:(F)V
const #17 = Asciz java/lang/System;
const #18 = class #17; // java/lang/System
const #19 = Asciz out;
const #20 = Asciz Ljava/io/PrintStream;;
const #21 = NameAndType #19:#20;// out:Ljava/io/PrintStream;
const #22 = Field #18.#21; // java/lang/System.out:Ljava/io/PrintStream;
const #23 = Asciz <init>;
const #24 = Asciz Code;
const #25 = NameAndType #23:#8;// "<init>":()V
const #26 = Method #4.#25; // java/lang/Object."<init>":()V
const #27 = Asciz main;
const #28 = Asciz ([Ljava/lang/String;)V;
const #29 = Asciz _x;
const #30 = Asciz I;
const #31 = NameAndType #29:#30;// _x:I
const #32 = Field #2.#31; // _test10._x:I
const #33 = Asciz _y;
const #34 = Asciz F;
const #35 = NameAndType #33:#34;// _y:F
const #36 = Field #2.#35; // _test10._y:F
{
public static int _x;
Signature:
Ipublic static float _y;
Signature: F
public _test10();
Signature: ()V
Code:
Stack=1, Locals=1, Args_size=1
0: aload_0
1: invokespecial #26; //Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Signature: ([Ljava/lang/String;)V
Code:
Stack=2, Locals=1, Args_size=1
0: getstatic #22; //Field java/lang/System.out:Ljava/io/PrintStream;
3: getstatic #32; //Field _x:I
6: invokevirtual #13; //Method java/io/PrintStream.println:(I)V
9: getstatic #22; //Field java/lang/System.out:Ljava/io/PrintStream;
12: getstatic #36; //Field _y:F
15: invokevirtual #16; //Method java/io/PrintStream.println:(F)V
18: return
}
Once again, the relevant code is marked red. At the code offset 0, Java code generator pushes a reference to the System.out type onto the stack. This is necessary because println method is defined within the System.out class. At the offset 3, Java bytecode generator pushes the value to be printed onto the stack, which is an integer (x). At that moment, the bytecode generator decides which println method to use: println(integer), println(float), or println(). Signatures ()V, (I)V, and (F)V correspond to println(), println(integer), println(float). Using the instruction invokestatic (obviously to invoke static member method) the code generator calls the println method, which pops values from the stack and performs the operation of printing the appropriate values to the standard output. Similarly, printing of floating point values is performed starting at the code offset position 9.
The reader is encouraged to reference JavaBytecodeGenerator::EmitWritelnStatement() method.
Loops
Translation of loops as performed by the Java bytecode generator is different from the MIPS code generator. This is due to the fact that JVM does not support labels. Loop translation in Java bytecode generator is simply implemented by using the offset and the “goto” instruction. Following is the pseudocode:
1.Evaluate(OpAssign) - LoopVariable contains initial value
2.Store byte position for later reference
3.Evaluate(Expression) - result will be pushed on stack
4.Compare(Expression, LoopVariable)
- if true then jump to end position
- If keyword "downto" is used then comparison should be LoopVariable >= Expression
- If keyword "to" is used then comparison should be LoopVariable <= Expression.
5.Evaluate(Statement)
6.Modify LoopVariable
- If keyword "downto" is used then Decrease(LoopVariable)
- If keyword "to" is used then Increase(LoopVariable)
7.Jump to stored position determined in (2)
8.This is end position
Looking at the pseudo code, we can see the strong similarities to MIPS code generation. However, during the Java bytecode generation, the byte code offset must be used, which is stored in the step 2. However, loop offset stored in the step 2 is utilized for offset calculation. “Goto” instruction expects byte offset relative to the program begin, which must be calculated. In addition, the loop-end must be recalculated once the complete loop is emitted.
Let’s look at the following example:
program test10;
var x : integer;
begin
for x:=0 to 10 do
begin
end
end.
Test10 program is translated to following:
public class _test10 extends java.lang.Object
minor version: 0
major version: 49
Constant pool:
const #1 = Asciz _test10;
const #2 = class #1; // _test10
const #3 = Asciz java/lang/Object;
const #4 = class #3; // java/lang/Object
const #5 = Asciz java/io/PrintStream;
const #6 = class #5; // java/io/PrintStream
const #7 = Asciz println;
const #8 = Asciz ()V;
const #9 = NameAndType #7:#8;// println:()V
const #10 = Method #6.#9; // java/io/PrintStream.println:()V
const #11 = Asciz (I)V;
const #12 = NameAndType #7:#11;// println:(I)V
const #13 = Method #6.#12; // java/io/PrintStream.println:(I)V
const #14 = Asciz (F)V;
const #15 = NameAndType #7:#14;// println:(F)V
const #16 = Method #6.#15; // java/io/PrintStream.println:(F)V
const #17 = Asciz java/lang/System;
const #18 = class #17; // java/lang/System
const #19 = Asciz out;
const #20 = Asciz Ljava/io/PrintStream;;
const #21 = NameAndType #19:#20;// out:Ljava/io/PrintStream;
const #22 = Field #18.#21; // java/lang/System.out:Ljava/io/PrintStream;
const #23 = Asciz <init>;
const #24 = Asciz Code;
const #25 = NameAndType #23:#8;// "<init>":()V
const #26 = Method #4.#25; // java/lang/Object."<init>":()V
const #27 = Asciz main;
const #28 = Asciz ([Ljava/lang/String;)V;
const #29 = Asciz _x;
const #30 = Asciz I;
const #31 = NameAndType #29:#30;// _x:I
const #32 = Field #2.#31; // _test10._x:I
const #33 = int 0;
const #34 = int 10;
{
public static int _x;
Signature:
Ipublic _test10();
Signature: ()V
Code:
Stack=1, Locals=1, Args_size=1
0: aload_0
1: invokespecial #26; //Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Signature: ([Ljava/lang/String;)V
Code:
Stack=2, Locals=1, Args_size=1
0: ldc_w #33; //int 0
3: putstatic #32; //Field _x:I
6: ldc_w #34; //int 10
9: getstatic #32; //Field _x:I
12: if_icmplt 26
15: getstatic #32; //Field _x:I
18: iconst_1
19: iadd
20: putstatic #32; //Field _x:I
23: goto 6
26: return
}
Once again, the relevant code is marked red. As expected, the variable x is initialized to 0. Subsequently, the value to be compared is pushed onto the stack together with the loop variable. At the offset 12, both values are compared and if equality is detected the jump is performed (to code offset 26 - end of the loop), otherwise the operation is continued. The code offset 18 pushes either 1 or -1 onto the stack for addition (increase/decrease). Finally, the goto instruction sends the execution path back to the loop begin.
The reader is encouraged to reference JavaBytecodeGenerator::EmitForLoop() method.
File Naming Convention
Upon successful compilation, the compiler generates a class file with the extension “*.class”. Similar to MIPS assembler, the file and the class name is derived from the program name with addition of the underscore character (which precedes both of those). For instance, if the program name is “test10” (from examples above), the class file name will be “_test10.class”.
Relevant Class: TinyPascal::Emitter::CAG_JavaBytecodeGenerator
Error Reporting
One of the fundamental issues of compiler design is the error reporting and recovery during the parsing step of the compilation. As already noted, TinyPascal utilizes the Spirit parser framework for parsing and abstract syntax tree generation. Consequently the error recovery depends heavily on the framework’s capability do perform such function.
At this point, the Spirit does not perform any parsing error recovery. The parsing is rather aborted after the first syntax error. As consequence, each syntax error must be detected using separate compilation process. In addition, Spirit generates the abstract syntax tree only upon successful parsing phase. In case that the parsing phase fails, Spirit simply deletes all previously created nodes.
TinyPascal Error Reporting
In its simplest form, the framework does not report the position at which the parsing failed. In its simplest form, Spirit reports only if the parsing was successful. In order to detect the position at which the parsing failed, separate object had to be created to store iterator’s position, at which the parsing failed. Spirit provides basic structure that monitors the iterator position and backtracks to the position where the parsing failed. The template class utilized for such functionality is position_iterator<> class.
Looking at the Spirit source code, position_iterator<> class is a wrapper that stores the iterator position before each rule is parsed. After successful parsing of the rule, the iterator position is moved to the next successful parsing point. As with all systems, there are advantages and disadvantages of such error reporting. The advantage is that error position is revealed. However, the disadvantage is that the error reporting might get inaccurate, if the rule definition is too long and the error occurs at the end of rule. In such case the error position is reported to be at the beginning of the rule, which is at times confusing.
However, it is important to stress that TinyPascal provides satisfactory level of error reporting. Spirit provides enough flexibility for the project of this size. Larger projects might require better and more sophisticated error reporting.
Compiler Class Diagram
TinyPascal is composed of multiple C++ classes. Classes are segmented by namespace. All namespaces are defined within the master namespace called TinyPascal. Following are namespaces and their definitions:
- Emitter – contains code emitting classes
- Parser – contains Spirit parser definitions
- Semantics – contains classes that are responsible for semantic checking
Following are TinyPascal classes and their brief descriptions:
- TinyPascal::CAG_TPMessageLog – contains all warnings and errors by providing static members to all classes for error/warning reporting.
- TinyPascal::CAG_TPCompiler – responsible for compiling TinyPascal code by utilizing all TinyPascal classes.
- TinyPascal::Parser::CAG_TinyPascalGrammar – Spirit definition of TinyPascal grammar.
- TinyPascal::Parser::CAG_TinyPascalSkipper – Spirit definition of TinyPascal skipper. In this way comments are ignored as well as all whitespace characters (tabs, newlines, spaces, …)
- TinyPascal::Emitter::CAG_CodeGenerator – base class for all code generators.
- TinyPascal::Emitter::CAG_JavaBytecodeGenerator – responsible for creating java class file from TinyPascal abstract syntax tree generated by Spirit.
- TinyPascal::Emitter::CAG_SPIMCodeGenerator – responsible for creating MIPS assembler file from TinyPascal abstract syntax tree.
- TinyPascal::Semantics::CAG_TPSymbolTable – responsible for building and accessing symbol table constructed from TinyPascal abstract syntax tree.
- TinyPascal::Semantics::CAG_TPTypeChecker – responsible for type checking and type derivation for all nodes of abstract syntax tree.
Following is the class diagram:
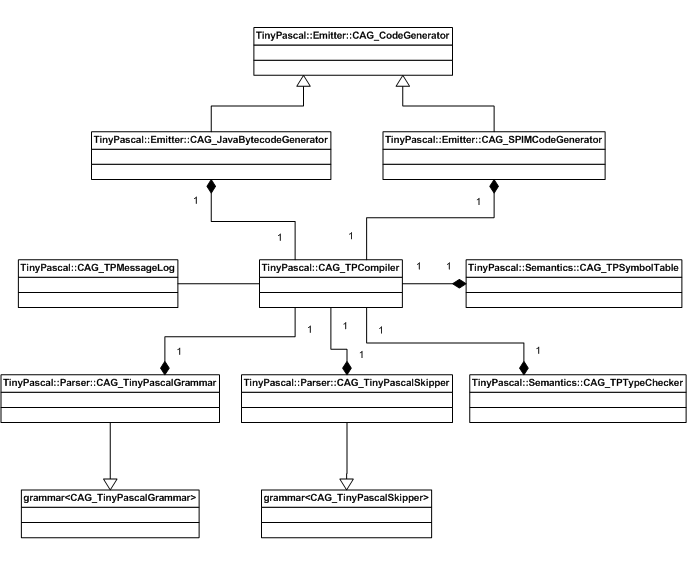
TinyPascal Editor
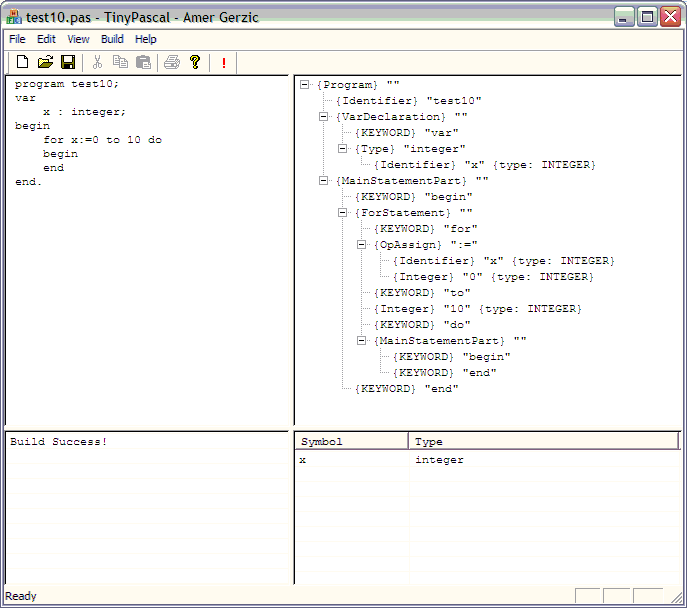
The screen shot above presents the TinyPascal user interface included with the TinyPascal compiler. In the upper left corner, we can see the program editor. Lower left corner displays all errors and warnings that occur the during compilation. Upper right corner displays the abstract syntax tree of the program. AST includes the type derivation and appropriate rule names that are responsible for parsing each AST node/sub-tree. Finally, the lower right corner displays the symbol table.
References
Download
Download Source Code - TinyPascal.zip (117.19 kb)